December 19th, 2007 edited by paulgear
Article submitted by Paul Gear. Please help DPOTD by submitting good articles about software you like!
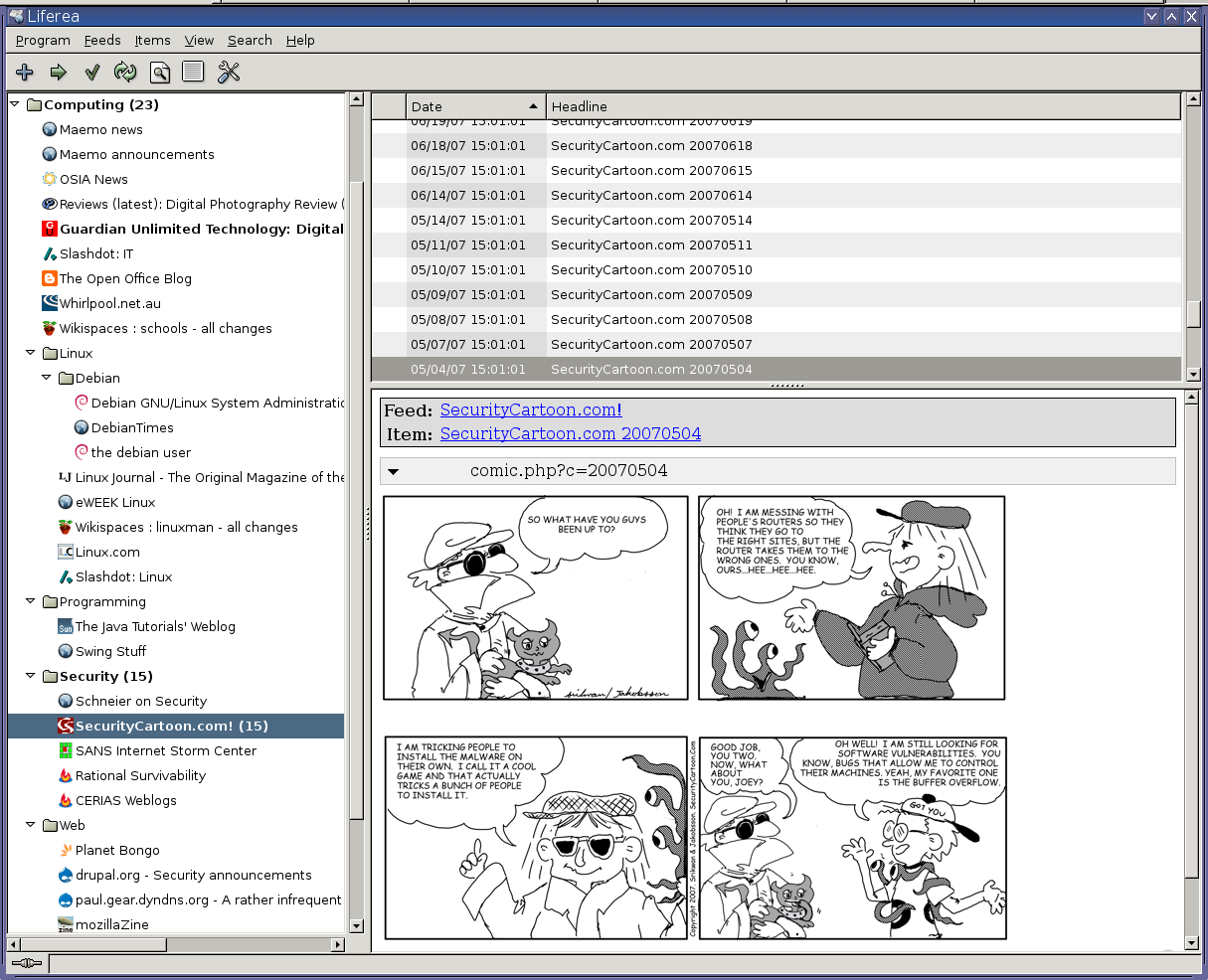
I recently discovered Liferea, an RSS reader/aggregator that uses Mozilla’s xulrunner as its web browsing engine. Its interface resembles that of a mail client such as Mozilla Thunderbird (a.k.a. icedove), and it works in much the same way, marking items as read when you click on them. Here’s a screen shot of Liferea in action:
Useful features include:
- Items in feeds may be flagged for later reference, and viewed in a separate “Flagged” folder
- Custom folder hierarchies for organising feeds
- “Heads-up display” on-screen notifications
- Selectable web browser (either internal, or any of the GNOME options)
Installation is typically straightforward using the standard package management tools on Debian or Ubuntu. A GNOME menu item is automatically created, and I was immediately productive after finding the basic menu items. Each feed has a number of options available, and Liferea will intelligently choose an appropriate refresh interval for each feed, or use your default if you prefer that instead.
One feature that would be useful to add to Liferea (this review is based on version 1.0.27 from Debian etch) is emailing of links, but this is easily worked around by opening in an external browser, and using the email link option from there.
Despite discovering it largely by accident (I saw it in the user agent portion of my blog’s Apache log), Liferea has become a mainstay desktop application for me. If you don’t find Liferea appropriate for your needs, you might want to check Wikipedia’s list of feed aggregators for one more appropriate to your needs.
Liferea has been in Debian since at least sarge and Ubuntu since at least dapper (it was in the universe repository prior to feisty).
Posted in Debian, Ubuntu | 10 Comments »
December 16th, 2007 edited by Alexey Beshenov
Article submitted by Zhao Difei. We are running out of articles! Please help DPOTD and submit good articles about software you like!
HTTrack is a powerful tool that allows you to download / mirror a website to a local location.
Basically, HTTrack follows the links of the original website, recursively downloads them to the local directory while re-arranging the hyper-links structure so you can just simply open a downloaded HTML file and browse at the local machine. In contrast, the recursive mirror function of Wget will not rearrange the hyper-links on the web pages you downloaded, so they might still be pointing to remote locations.
HTTrack is a powerful tool but the syntax is very simple, let’s have a look at the basic usage:
$ httrack –help
HTTrack version 3.41-3 (compiled Jul 3 2007)
usage: httrack <URLs> [-option] [+<URL_FILTER\>] [-<URL_FILTER>] [+<mime:MIME_FILTER>] [-<mime:MIME_FILTER>]
A simple example that copies the debian.org website to the local “httrack” directory:
$ mkdir httrack
$ cd httrack/
$ httrack debian.org
Mirror launched on Sun, 30 Sep 2007 18:05:40 by HTTrack Website Copier/3.41-3+libhtsjava.so.2 [XR&CO'2007]
mirroring debian.org with the wizard help..
* debian.org/intro/about.ro.html (17854 bytes) - OK
HTTrack can also apply download filters, you may have noticed the “*_FILTER” things from the httrack usage line above, the plus sign + means to download a specific patter, and the minus sign - means to avoid download. The following examples (mirroring slashdot) show a simple usage of filters, the first one will not download items from the apple.slashdot.org site, and the second one will not download items which have a MIME image/jpeg type, please notice that you can still view the things you did not download if you have the Internet connection available, because HTTrack will arrange the hyperlinks for you:
To download two sites that share lots of common links, you can do:
$ httrack www.microsoft.com www.evil.com
There are still many options and more advanced usages left, interested readers may always read the manual. HTTrack is available in Debian from oldstable Sarge to unstable Sid and for Ubuntu from Dapper to Gutsy.
Posted in Debian, Ubuntu | 4 Comments »
December 12th, 2007 edited by Tincho
Entry submitted by John Carlyle-Clarke. DPOTD needs your help, please contribute!
I wanted to recover data from a failing hard drive, and asked on IRC if any good tools existed for Ubuntu. Someone pointed me towards GNU ddrescue (named gddrescue in Debian and Ubuntu), which is designed for rescuing data from any file or block device.
Don’t confuse this with dd_rescue (package name ddrescue). GNU rescue is a better tool.
The GNU site describes GNU ddrescue as a data recovery tool, and lists these features:
- It copies data from one file or block device (hard disc, CD-ROM, etc) to another, trying hard to rescue data in case of read errors.
- It does not truncate the output file if not asked to, so every time you run it on the same output file, it tries to fill in the gaps.
- It is designed to be fully automatic.
- If you use the log file feature of GNU ddrescue, the data is rescued very efficiently (only the needed blocks are read). Also you can interrupt the rescue at any time and resume it later at the same point.
- The log file is periodically saved to disc. So in case of a crash you can resume the rescue with little recopying.
- If you have two or more damaged copies of a file, CD-ROM, etc, and run GNU ddrescue on all of them, one at a time, with the same output file, you will probably obtain a complete and error-free file. The probability of having damaged areas at the same places on different input files is very low. Using the log file, only the needed blocks are read from the second and successive copies.
- The same log file can be used for multiple commands that copy different areas of the file, and for multiple recovery attempts over different subsets.
The algorithm of GNU ddrescue is as follows:
- Optionally read a log file describing the status of a multi-part or previously interrupted rescue.
- Read the non-damaged parts of the input file, skipping the damaged areas, until the requested size is reached, or until interrupted by the user.
- Try to read the damaged areas, splitting them into smaller pieces and reading the non-damaged pieces, until the hardware block size is reached, or until interrupted by the user.
- Try to read the damaged hardware blocks until the specified number of retries is reached, or until interrupted by the user.
- Optionally write a log file for later use.
To use it, you need to install gddrescue, but it is invoked as ddrescue. This is confusing, but it’s because dd_rescue had already taken the name.
The syntax is simple and the man and info documents are pretty good. Here is an example session with a data CD (no errors found).
$ ddrescue -v /dev/cdrom Recovered.iso ddrescue.log
About to copy 101763 kBytes from /dev/cdrom to Recovered.iso
Starting positions: infile = 0 B, outfile = 0 B
Copy block size: 128 hard blocks
Hard block size: 512 bytes
Max_retries: 0 Split: yes Truncate: no
Press Ctrl-C to interrupt
Initial status (read from logfile)
rescued: 0 B, errsize: 0 B, errors: 0
Current status
rescued: 101763 kB, errsize: 0 B, current rate: 3801 kB/s
ipos: 101711 kB, errors: 0, average rate: 2702 kB/s
opos: 101711 kB
Useful links:-
Related software:-
gddrescue is available in Debian since Etch, and in Ubuntu since Edgy. It was started by Antonio Diaz Diaz in 2004.
Posted in Debian, Ubuntu | 6 Comments »
December 9th, 2007 edited by Tincho
Article submitted by Maurizio Pedraglio. We are running out of articles! Please help DPOTD and submit good articles about software you like!
Clusterssh is a graphical utility that allows you to open several ssh connections and execute commands simultaneously in all of them. I find it powerful in many cases, for example when I’ve to perform a dist-upgrade on many different servers.
It provides a small window to control the sessions, and one xterm window for each one of them. Here are some screen shots using it on Ubuntu and Gnome 2.20.
You can open a ssh session simply clicking on “Host” and then “Add Host”.
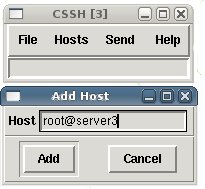
Type user@server in the “Add Host” window and a new shell will appear in a new window.
You’ll be able to open n different ssh session versus n hosts. You should focus the input box in the controlling window to send commands to all the shells at once.
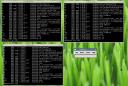
If you want to execute a command only in a single host, simply focus the right shell. The other shells won’t receive anything, and the command will take effect only on the selected host.
If you want to detach a shell from the parallel command execution, simple uncheck it in the “Host” menu. In the case below commands will be executed on host 192.168.15.104 and localhost1 but not on localhost
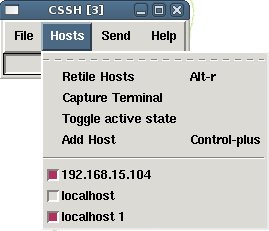
Others commands available: use “Toggle active state“ to uncheck all host; “Retile” allows you to reorganise windows in the desktop. Clusterssh can also be launched from the command line, just type in a shell:
cssh serverA serverB … serverN
Clusterssh has been available both in Debian and Ubuntu since a long time ago
Posted in Debian, Ubuntu | 12 Comments »
December 5th, 2007 edited by Tincho
Article submitted by Tomas Pospisek. Please help DPOTD by submitting good articles about software you like!
VirtualBox is a piece of software that uses virtualisation to simulate a PC. With it you can run Windows, Open BSD or even Linux from your Debian system. Since it also runs on Windows and Mac OS, you can use it to run Debian from that other non-free OS. Note however that it only works on x86 and x86_64 hosts.
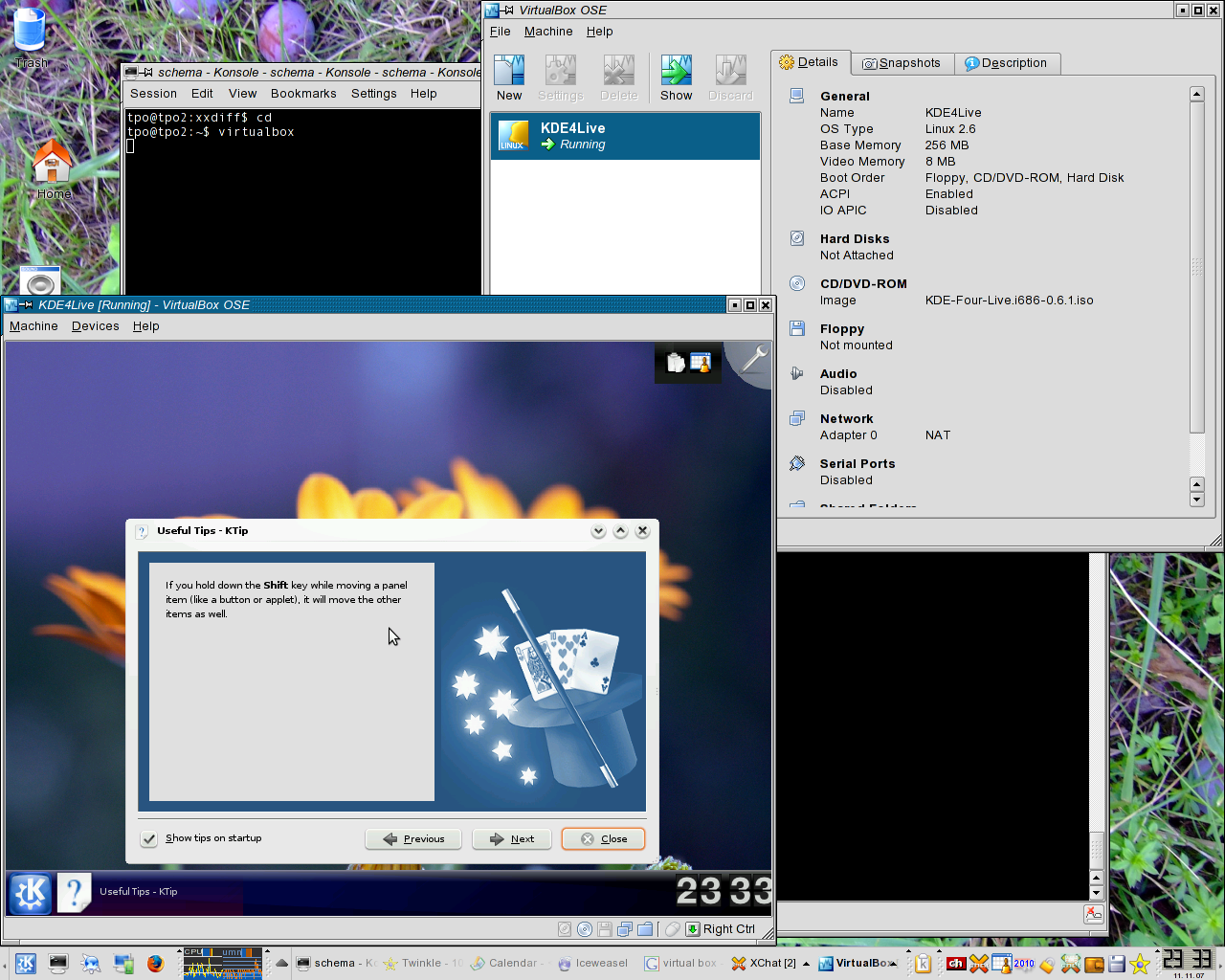
You can use it if you want to test or have a look at a live CD distribution or to help the KDE project test the new KDE4 without messing up your current desktop.
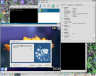
You can do all this in a nice and hassle free GUI, driven by menus or application wizards. Here you can see the mentioned "KDE Four Live" CD booted up and ready within VirtualBox.
VirtualBox requires to load its own set of kernel modules and won’t start without them. There is a package providing pre-built modules for the stock kernels in testing, you will need to manually install the correct version for your kernel. If those packages doesn’t suit you, you will need to compile them; the standard Debian way to do this would be:
$ sudo apt-get install virtualbox-ose virtualbox-ose-sources module-assistant
$ sudo module-assistant prepare virtualbox-ose
$ sudo module-assistant auto-install virtualbox-ose
$ ls /usr/src/virtualbox-ose-modules-*
$ sudo dpkg -i /usr/src/virtualbox-ose-modules-*.deb
That last line will need to be re-written to pick the virtualbox-ose-modules package that corresponds to your kernel.
You’ll also need to add the users that should be allowed to run VirtualBox to the vboxusers group. I’m adding the current user here:
$ sudo adduser `whoami` vboxusers
Now you have to re-login so that your process context picks up the fact that you now belong to then vboxusers group. You can do that by "su"ing into yourself:
$ su `whoami` -
And here you go:
$ virtualbox
Note for those who like to know how it works: VirtualBox tries to run native code whenever possible, when it’s necessary it uses dynamic recompilation as QEMU does. It also moves guest code intended to run on ring 0 to ring 1, and because of this it doesn’t use the VMX features from the processor too much. See the technical documentation for details.
The virtualbox-ose package is available in Debian testing and unstable, and in Ubuntu since Gutsy (if you’re thinking of upgrading to testing, be sure you are aware of the implications, before doing so!). There’s also a backport to the currently stable Debian "etch" release.
Posted in Debian, Ubuntu | 10 Comments »