Article submitted by Dean Serenevy. We are running out of articles! Please submit good articles about software you like!
You’ve heard of book and movie collection organizers, but Robby Stephenson’s tellico is a general purpose collection manager. This application can be used to store information about arbitrary collections of whatever tickles your fancy. Tellico is available from the tellico package in Debian since Sarge and in Ubuntu since Dapper. Tellico is a KDE application, but works fine in other desktop environments.
The Basics
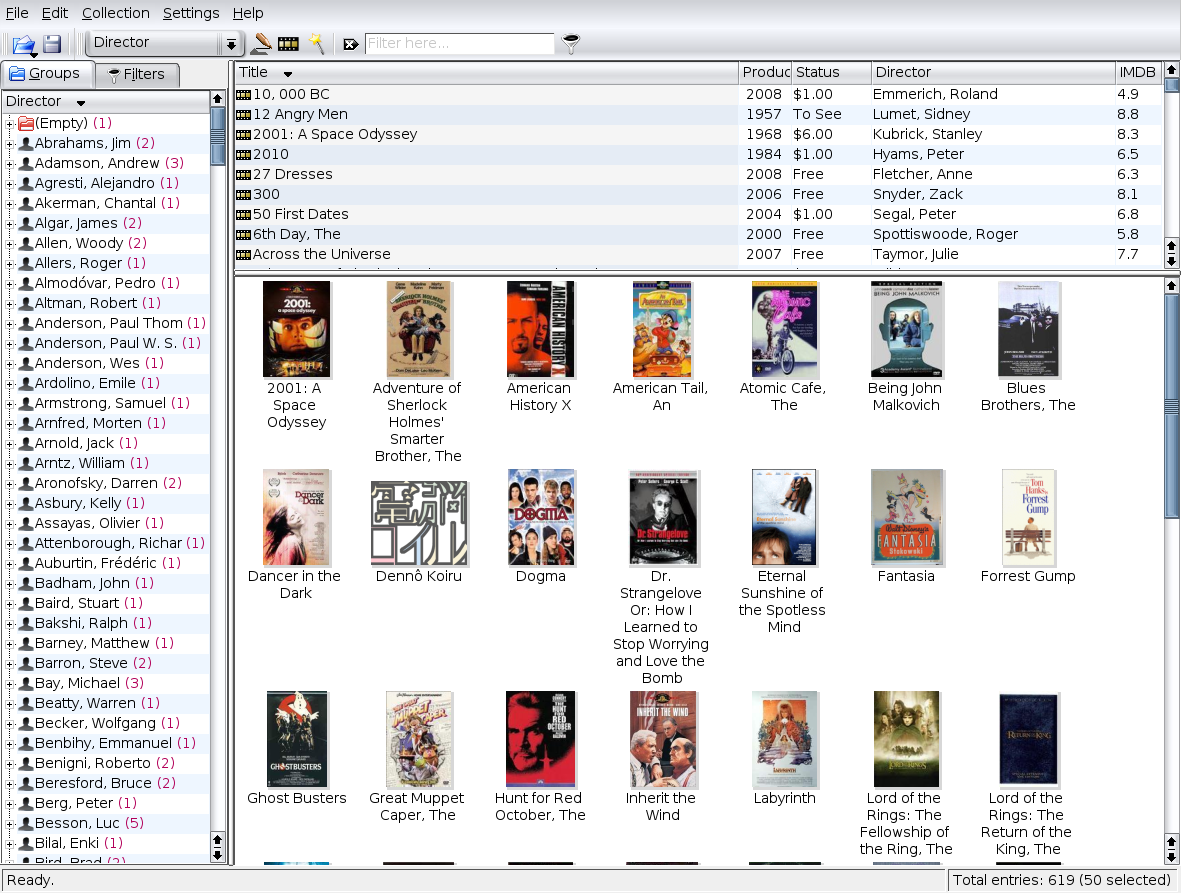
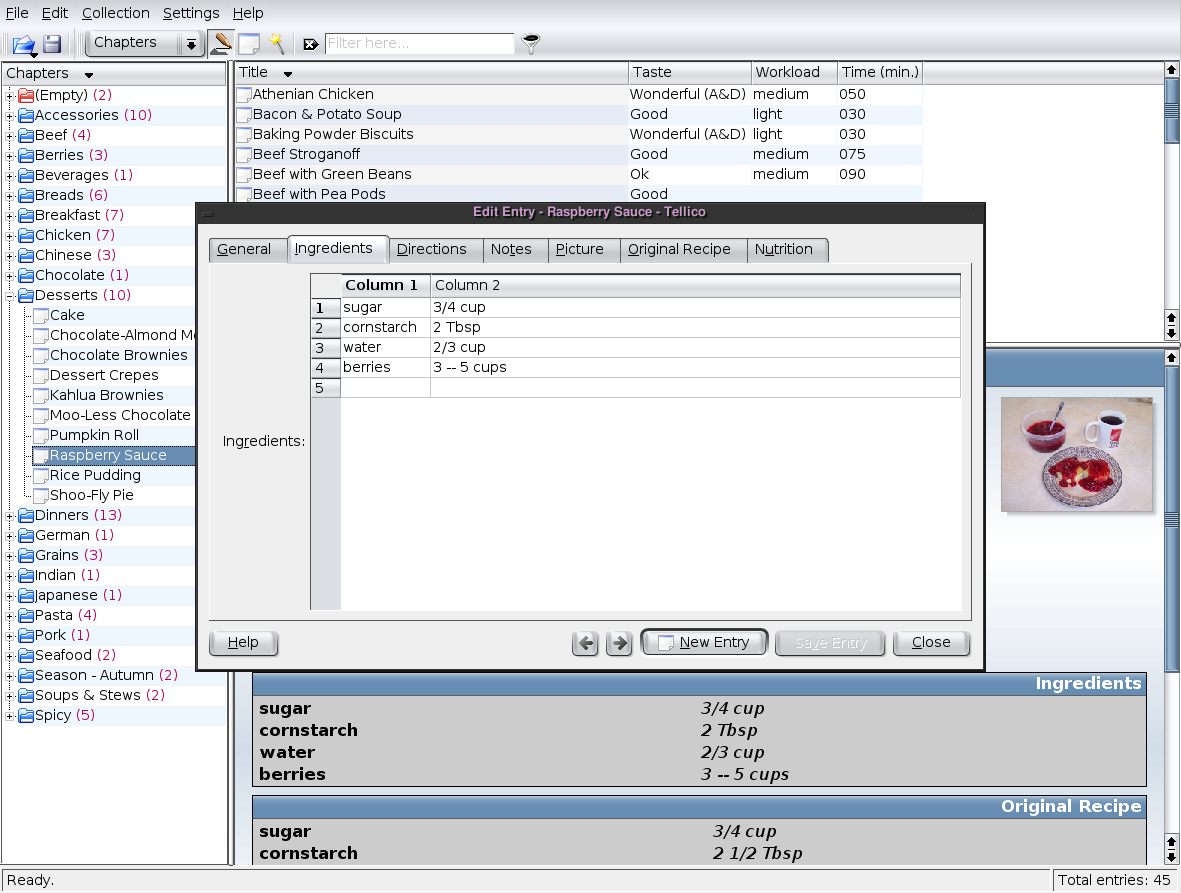
Like any good book or movie collection application, tellico presents the user with a multi-pane window that groups entries by some customizable criterion (I’ve grouped by director below), lists entries by some fields (customizable), and shows thumbnails.
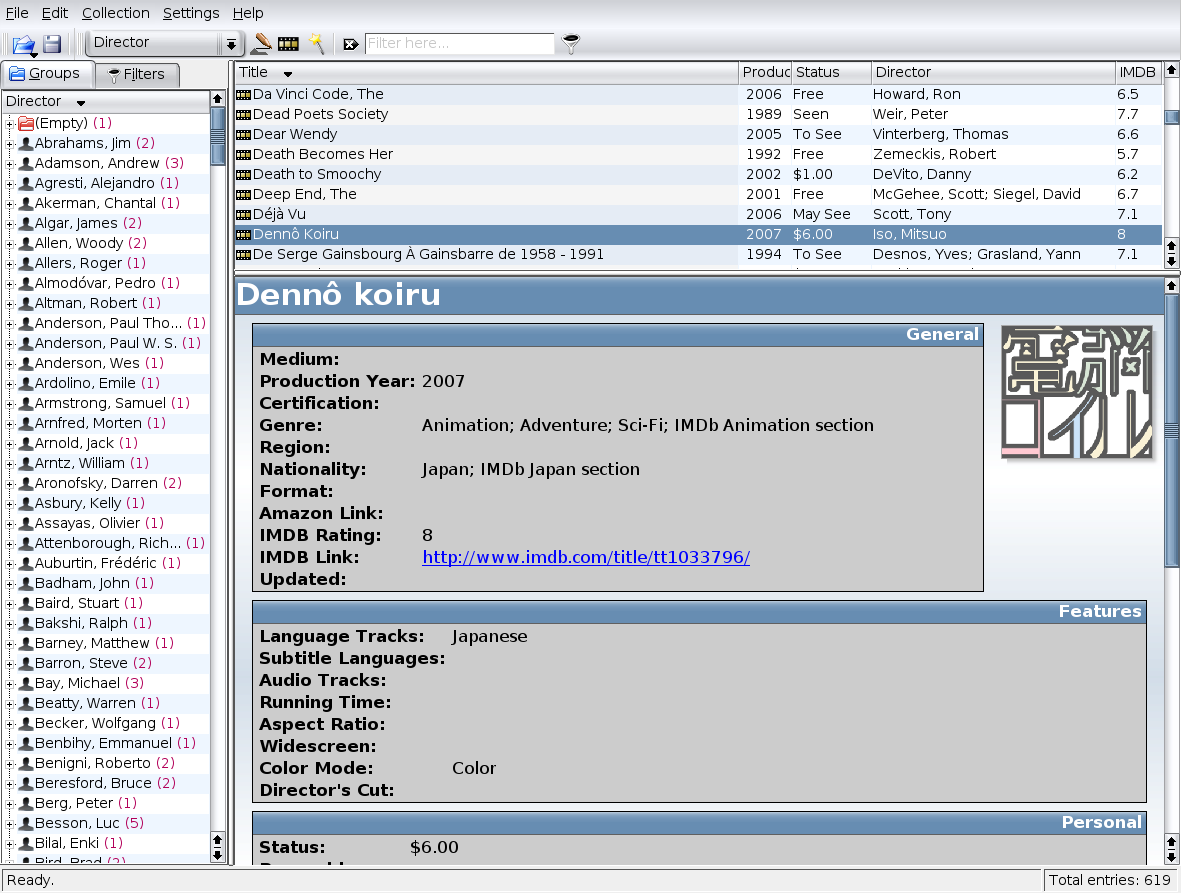
Selecting a list entry shows a more detailed view and a larger thumbnail. Clicking the image in this view launches your image editor.
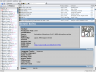
Most of the built-in collection types include search sources to make adding new entries easy. Tellico has default search sources for Amazon.com (US, Japan, Germany, United Kingdom, France, and Canada), IMDb (movie database), z39.50 servers (bibliographic database), SRU servers (bibliographic database), PubMed (Medicine bibliography), CrossRef.org (bibliographic database developed by a consortium of publishers), and some others. You can also write your own script that performs the search and returns entries in a supported format.
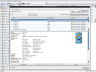
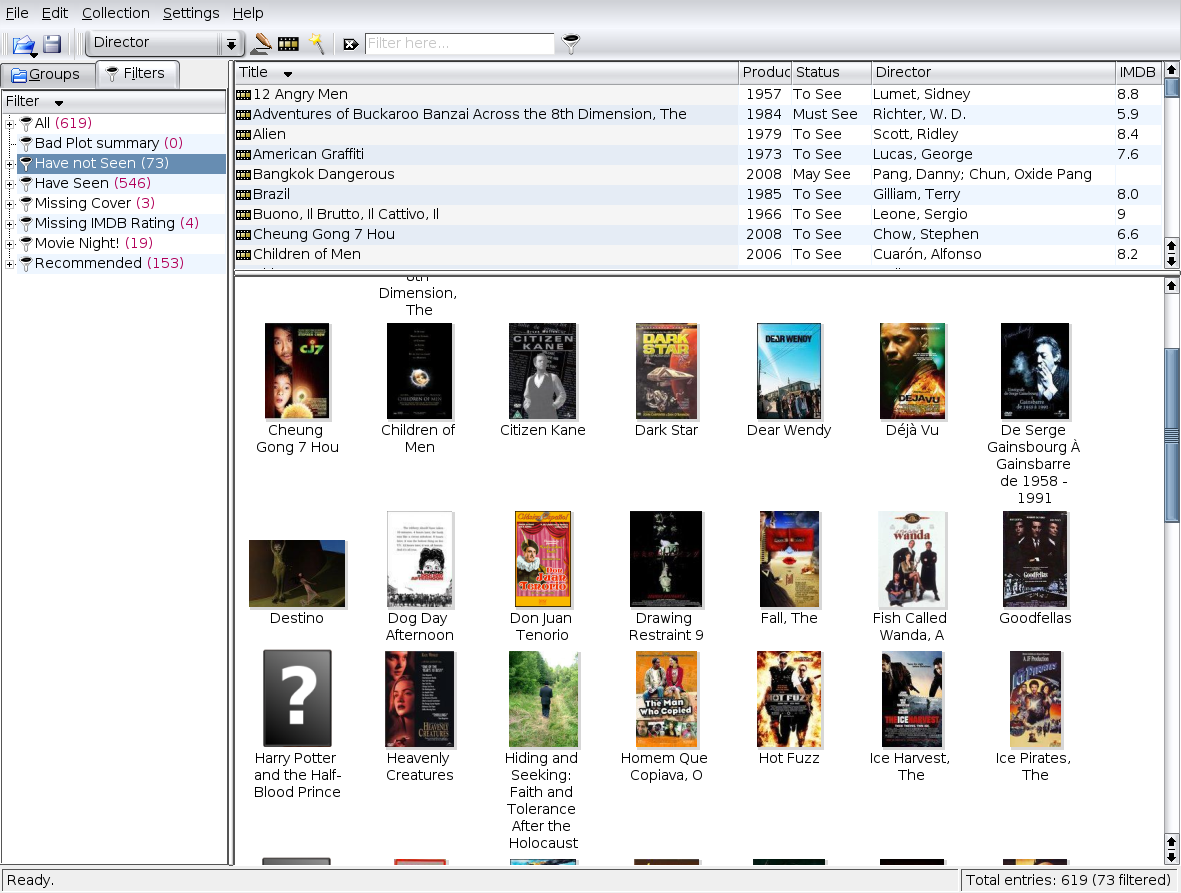
The search box will filter results based on regular expression queries. Complex filters can be named and will be saved with the collection file.
Beyond Books and Movies
Tellico’s built-in list of collection templates is already quite impressive. It provides default templates for books, bibliographies, videos, music, video games, coins, stamps, trading cards, comic books, and wines. However, users are free to modify, add, or remove fields in these collections or even create custom collections with arbitrary fields.
For example, I keep a collection of hyperplane arrangement examples in a custom tellico file. Tellico happily keeps a fully group-able and search-able record of my coefficient fields, polynomials, and other fields.
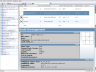
Editing a custom entry looks just like editing a standard record type. Fields are grouped by customizable categories.
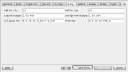
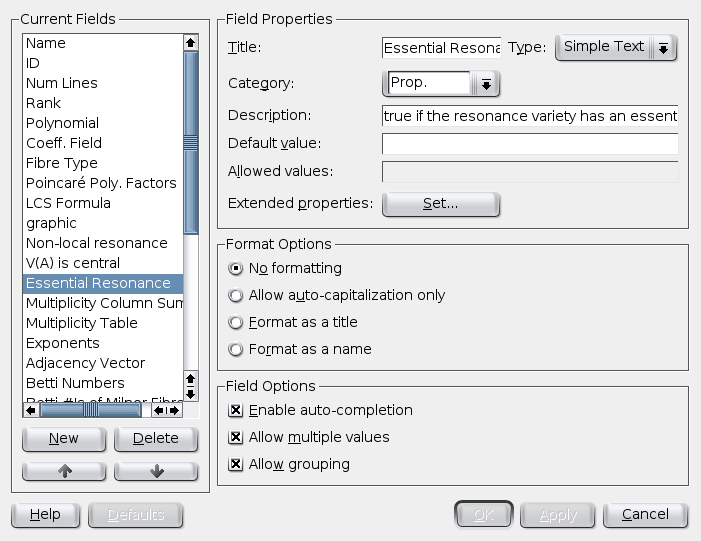
Modifying the collection fields is wonderfully simple. Your fields may be any of several field types including: text, paragraph, choice, checkbox, table, URL, date, and image. Field upgrading is supported between compatible field types.
Fields may be auto-formatted as names or titles if you wish. You can also control whether the field should support auto-completion (using existing entries in your collection), multiple values, or whether the field should appear in the grouping combo box.
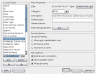
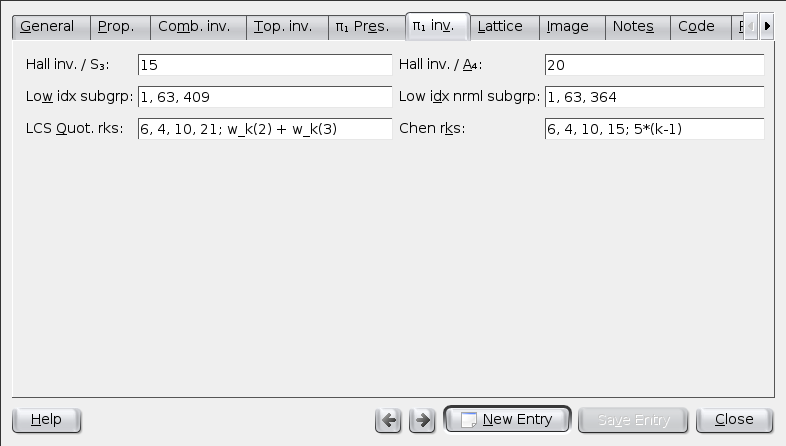
The paragraph field type supports basic HTML markup (used here in my bibliography collection). The red letters are KDE’s spell-check attempting to be useful.
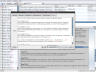
I use the table field type in my recipe collection.
Beyond the Application
Tellico can import and export data to and from many sources (Bibtex, CSV, PDF metadata, Alexandria, …). It can export your collections (even custom collections) to HTML and generate HTML reports in several styles. Tellico even has limited support for sending citations to OpenOffice.org Writer (though I have never used this feature).
Moreover, since Tellico stores its data in a fully documented XML file you can write XSLT or use any XML parser to transform the data file however you like.
Tellico supports loan tracking for any collection type. It also translated into more than ten languages.
The not so good
Tellico is somewhat laggy when loading hundreds or thousands of images from disk and occasionally when switching from thumbnail view to entry view. However, switching between entries is always fine and collections with fewer images are quick and responsive.
Alternatives
There are many special-purpose collection managers (most of which are listed on the tellico homepage), but tellico is one of the earlier general purpose managers. Some applications (such as GCstar) are becoming more general-purpose as they mature. Others (such as Stuffkeeper) are simply younger applications and are not yet stable. Tellico is a well-designed application and therefore can give even the special-purpose collection managers a run for their money.