xmlstarlet: Command Line XML Toolkit
March 22nd, 2009 edited by VichoArticle submitted by Vasily Faronov. Guess what? We still need you to submit good articles about software you like!
With the proliferation of XML-based formats, it is nice to have tools that manipulate XML documents in the traditional Unix-like fashion, as the good old grep(1), sed(1) and other tools do for plain text. xmlstarlet is one of such tools. In fact, it is an entire toolkit packed into one program: xmlstarlet can extract data from XML documents, alter them, validate them, and perform many other useful operations. xmlstarlet has been available in Debian since at least release 4.0 “etch”, and in Ubuntu since at least release 6.06 “Dapper Drake”.
Let’s look at a few features of xmlstarlet more closely.
Extracting Data from XML Documents
There is a flexible way of processing XML documents and extracting data from them — a language known as XSLT. Both Debian and Ubuntu provide utilities, such as xsltproc, to deal with XSLT. However, this language is not exactly terse, and it requires you to first compose a separate document defining the desired transformation, and then apply it to the original document. When all you want to do is extract a few values from a document, you’d like something more approachable.
xmlstarlet is your friend. It features a relatively simple command syntax for selecting data, based on an auxiliary language called XPath, which allows for addressing elements in XML documents in a style reminiscent of filesystem paths. Behind the scenes, xmlstarlet still generates XSLT code, and it helps to know the actual XSLT language, but simple queries can be done almost intuitively.
Suppose we’d like to get a list of the recent headlines from the Debian Package of the Day website. We can use xmlstarlet to extract titles from the site’s RSS feed, because RSS is an application of XML. In RSS, entry titles are contained in title elements, in turn contained in item elements, which are in channel elements under the root rss element. The feed itself can be easily fetched with wget(1). Our pipeline would then look like this:
$ wget -O - https://debaday.debian.net/feed/ 2>/dev/null | \ > xmlstarlet sel -t -m /rss/channel/item -v title -n Fonty Python: manage your fonts localepurge: Automagically remove unnecessary locale data vnstat: a console-based network traffic monitor rtpg-www: Please your dearest with rtorrent’s power iftop - display bandwidth usage on an interface by host atop: an ASCII full-screen performance monitor dstat: versatile tool for generating system resource statistics tellico: collection manager for books, videos, music, and a whole lot more atool: handling archives without headaches watch (from procps): execute a program at regular intervals, and show the output
The wget invocation is hopefully obvious (if it isn’t, just believe me that it downloads the feed and prints it to the standard output), so let’s dissect the xmlstarlet part.
sel, which stands for “select”, is the subcommand to invoke within xmlstalrlet — since it’s a toolkit, it contains a number of such subcommands.- The
-toption designates the beginning of a template — roughly, a group of processing instructions. - The
-moption specifies a match, and/rss/channel/itemis an XPath expression; together they translate to “for eachitemelement found under achannelelement under thersselement”. - Then we specify what to do for that match: in our case,
-v titleprints out the value of thetitleelement under the currentitem, and-nprints a newline separator.
The various options to xmlstarlet’s sel subcommand can be combined to produce fairly complex XSLT transformations. You can view the XSLT code generated by your command by adding the -C option.
Validating XML Documents
There are several ways of defining an XML document format, and the simplest of them is called document type definition, or DTD. A DTD defines which elements are allowed to appear in a document and what they can contain. DTDs for some popular formats, such as XHTML, are included in the Debian and Ubuntu archives. The val subcommand of xmlstarlet can validate documents against a DTD — that is, check if the documents comply with the formal requirements laid out in a DTD. In addition to DTD, xmlstarlet can also handle the more advanced XML Schema and RELAX NG languages.
As an example, let’s integrate xmlstarlet with gedit, the GNOME text editor, to enable easy validation of XHTML 1.0 Strict documents. We will need the w3c-dtd-xhtml package that contains the DTD files.
To validate against a DTD, xmlstarlet should be invoked with the val subcommand, the -d option (for “DTD”), and a path to the DTD file. As in the previous example, the document can be piped into xmlstarlet. We will integrate it into gedit by means of the latter’s “External Tools” plugin. Enable it by choosing “Edit” → “Preferences” → “Plugins” and marking “External Tools”. Then, in the “Tools” menu, select “External Tools” and click “New”. Name the tool as you wish, and optionally give it a description and a shortcut key. For “Command(s)”, enter this simple script:
#! /bin/sh xmlstarlet val -d /usr/share/xml/xhtml/schema/dtd/1.0/xhtml1-strict.dtd -
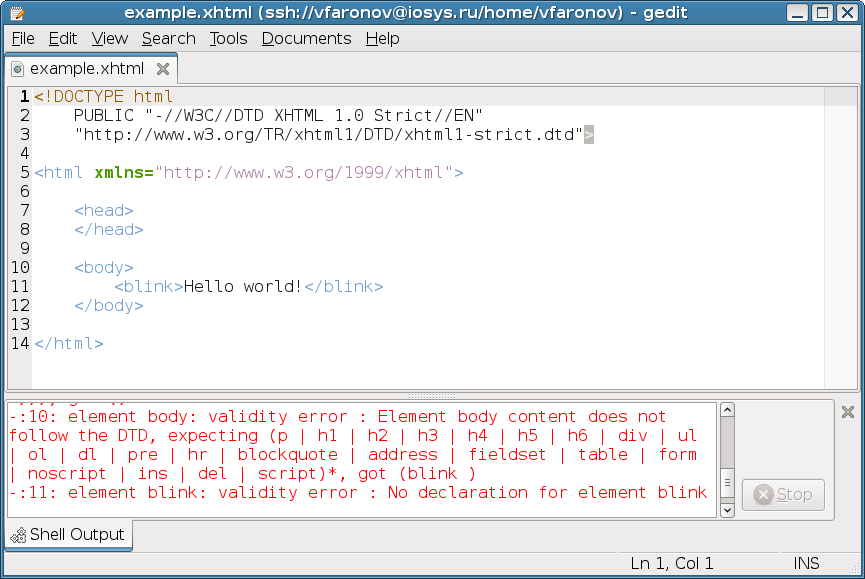 Choose “Current document” for input, “Display in the bottom pane” for “Output”, and set “Applicability” to “All documents”. And that’s it. You can now validate any document you open in gedit from the “Tools” menu — even if the document comes from a remote location by way of the GNOME virtual filesystem.
Choose “Current document” for input, “Display in the bottom pane” for “Output”, and set “Applicability” to “All documents”. And that’s it. You can now validate any document you open in gedit from the “Tools” menu — even if the document comes from a remote location by way of the GNOME virtual filesystem.
With some more effort, you can write a script to validate any document for which you have the DTD installed. (Hint: you may use xmlcatalog(1) from the libxml2-utils package to locate DTD files by their public identifiers.)
Other Uses
This article cannot cover many other features of this toolkit, such as editing XML documents (ed), listing their element structure (el), or pretty-printing (fo). You may want to check out the examples that come with the xmlstarlet package (/usr/share/doc/xmlstarlet/examples), and to the reference help available by invoking xmlstarlet ‹COMMAND› --help.
Related Tools
The Debian archive also contains the python-4suite-xml package, which among other things provides some command tools for XML processing similar to xmlstarlet. However, 4suite seems to be intended more as a Python package, and consequently its command tools appear to be less feature-complete than xmlstarlet.
For solving specific XML-related problems, such as converting XML to and from other formats, you may want to have a look at the more specialized packages available in Debian and Ubuntu. The Debian Reference has an overview of some of those.
Posted in Debian, Ubuntu | 2 Comments »