Article submitted by Gandalf Lechner. Please help DPOTD by submitting good articles about software you like!
So you work in a scientific environment and wonder how to organize bibliographic data, downloaded articles/preprints and links to online papers in such a way that…
- …you can easily browse through your collection of articles and search for particular publications
- …you can automate the process of creating citations and references when typing your own articles in LaTeX
- …you can include new articles in your collection from online repositories with a few clicks
- …you keep full control over the stored data by being able to access the BibTeX “source” at any time
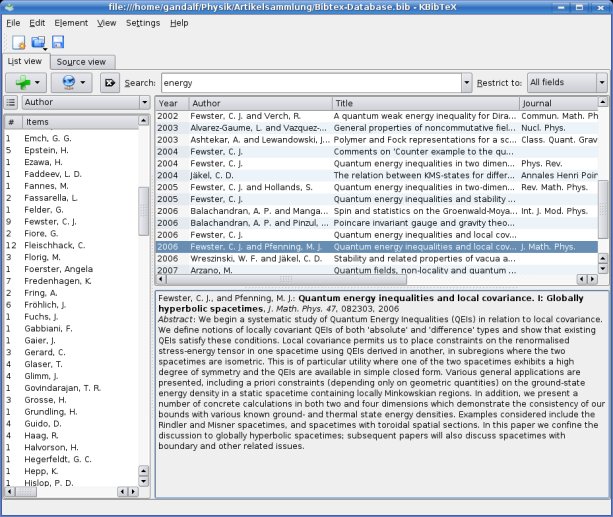
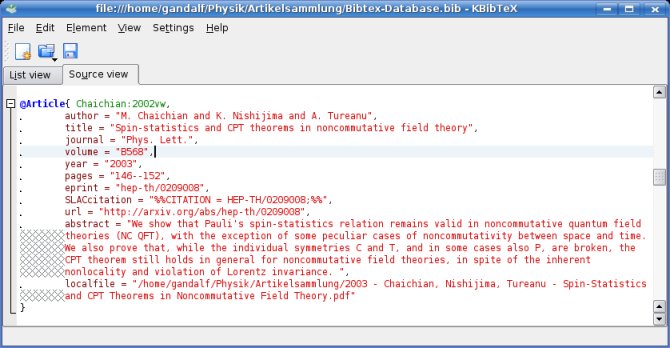
Then KBibTeX is the program you are looking for. It uses the BibTeX format to store bibliographic data and provides a nice KDE interface to search through your BibTeX files. Its main window looks like this:
Managing your References
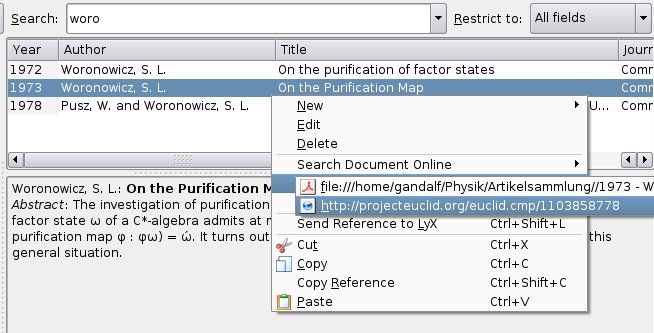
Since you can sort your data by various criteria such as author, title, year or journal, you will usually find the article you are looking for instantly. You then have the choice of either checking the reference data and abstract directly within KBibTeX, or opening the associated URL or pdf file. This provides the basic functionality necessary for using KBibTeX as a frontend to your collection of articles. More advanced features include the possibilities to attach keywords (tags) to articles, or to carry out online searches for a given paper, using Citebase, Google, Google Scholar, PubMed, Scientific Commons or SpringerLink, to name just a few available search methods.
Adding new articles manually…
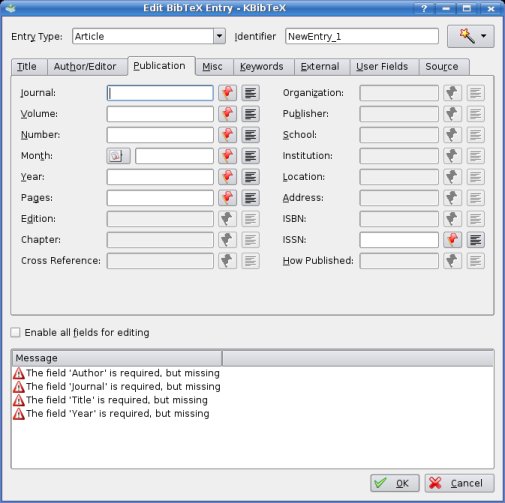
In KBibTeX, you can add new bibliographic data to your collection in two ways, either manually or automatically by using online article repositories. If you add new papers manually, you have a multitude of possibilities for configuring the input - from basics such as the kind of BibTeX entry (article, book, IEEE, PhDThesis, Unpublished, …) over all the usual BibTeX data (authors, editors, journal, publication date, pages, ISBN, publisher, institution, …) to more advanced information such as keywords, abstracts, digital object identifiers (DOI), associated URLs and PDF files, and entirely user-defined fields.
…or automatically: Integration of online databases
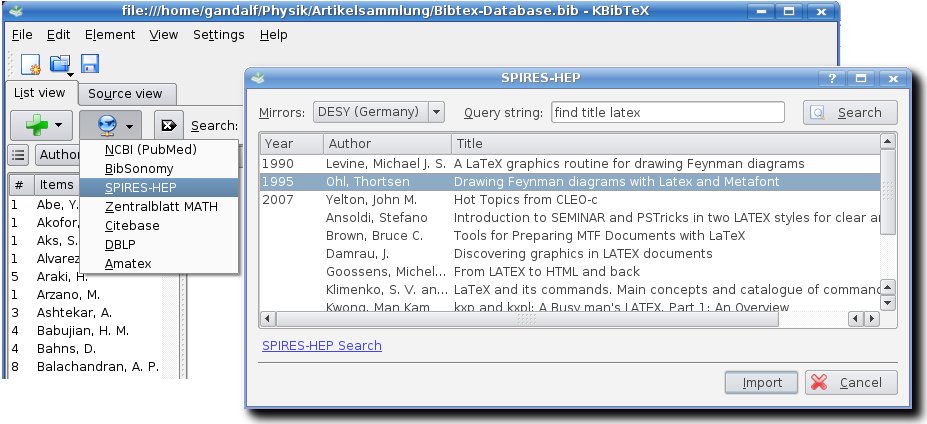
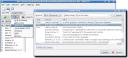
One feature I particularly like about KBibTeX is the growing number of online article databases it supports. In version 0.2, the list includes PubMed, BibSonomy, SPIRES, Zentralblatt MATH, Citebase, DBLP and Amatex, which makes the program useful for people working in many different subjects, such as medicine, physics, mathematics or computer science. In the screenshot below you see how easily a SPIRES search is carried out within KBibTeX, and how the found bibliographic data can be imported into your BibTeX file.
Citation manager and interaction with LyX/Kile
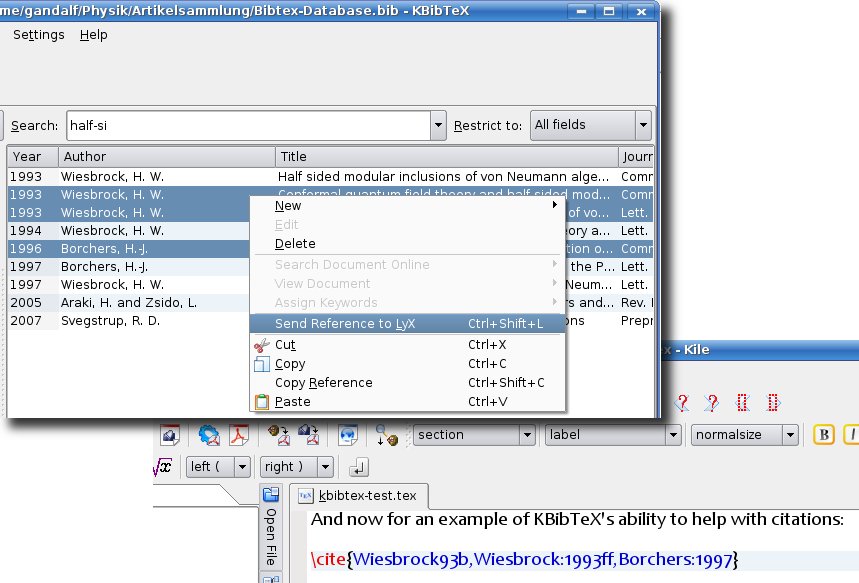
One main field of use for KBibTeX is its ability to greatly assist you with creating citations in LaTeX documents. When typing a document using an editor such as Kile (or LyX), just select the articles you want to cite within KBibTeX and send them to the editor using a drop down menu or a hot key:
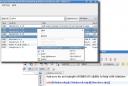
In particular, you don’t have to care about tedious BibTeX identifiers any more, since these are effectively administered by KBibTeX.
BibTeX source
What people used to editing their BibTeX files manually will like is that this possibility still exists in KBibTeX - by switching to Source View you can always adjust your BibTeX data manually if you like.
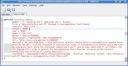
By strictly adhering to the BibTeX format, files edited by KBibTeX are also open for use with any other program understanding BibTeX.
Final comments
For Linux users working frequently with LaTeX and BibTeX, KBibTeX offers many nice features which can greatly simplify otherwise tedious and time consuming tasks. In view of its bibliography manager functions, KBibTeX is right now the best approximation to the great - but unfortunately still non-existing - KPapers. Hopefully it will develop further in this direction in the near future…
Links
Further information about KBibTeX can be found on the website of the developer Thomas Fischer, or at kde-apps.org. For information on the KBibTeX mailing list, go here.
KBibTeX 0.1.5 is available in Debian ‘Etch’ (stable) and Ubuntu. The fresh version 0.2, which has numerous improvements over 0.1.5, should soon be available as Debian or Ubuntu packages, too. In the meantime, you can of course grab the source code and compile it, which is a quick “configure - make - sudo make install” mission.